Next: A klasszikus példa EM Up: Az EM algoritmus Previous: A maximum likelihood becslés Tartalomjegyzék
Sokszor a likelihood függvényt nehéz maximalizálni, vagy nem is lehet a megoldást felírni zárt alakban. Ekkor numerikus módszerekre van szükség. Sok esetben kézenfekvően tekinthetünk úgy a mintára, mint egy bővebb mintának egy látható részére, ahol ez a bővebb minta olyan statisztikai mezőből származik, amiben könnyű maximalizálni a likelihood függvényt. A gond az, hogy ennek a bővebb mintának csak egy részét, az eredeti mintát ismerjük. Ezt úgy lehet megoldani, hogy a hiányzó rész eredeti minta szerinti feltételes várható értékét vesszük valamilyen kiindulási paraméter választással a bővebb minta likelihoodjának maximalizálása során. Így bizonyíthatóan jobb paramétert kapunk, vagyis ezzel a paraméterrel az eredeti likelihood értéke az eredeti mintában nagyobb, illetve nem kisebb, mint a kiindulási paraméterrel volt. Ezt az eljárást folytatva az új paraméterrel, majd tovább iterálva lépésenként jobb, és az eredeti likelihood egyenlet megoldásához konvergáló, paraméterek sorozatát kapjuk, ha az eredeti likelihoodnak egyetlen stacionárius pontja van. A bővebb mintát hívjuk teljes adatrendszernek, annak látható részét pedig hiányos adatrendszernek.
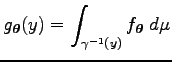
egyenlőség. Ekkor tetszőleges